 Jouw data. Jouw Ai.
Jouw data. Jouw Ai. 

Tech deep dive: hoe Ai‑agents draaien op eigen data en binnen je eigen omgeving
In veel organisaties wordt Ai nog gezien als iets nieuws naast bestaande systemen.
Een tool, een assistent, een chatbot.
In de praktijk werkt het anders.
Ai-agents functioneren niet naast je landschap, maar eroverheen.
Als een laag die bestaande systemen verbindt, interpreteert en aanstuurt.
En juist die positie bepaalt of het werkt of complexiteit toevoegt.
Lees ook: is jouw organisatie Ai-agent-ready?
Een agent is geen losse tool
Veel implementaties starten vanuit tools.
Een chatbot, een assistant, een integratie.
Iets wat je toevoegt aan wat er al is.
Maar een Ai‑agent doet iets fundamenteel anders.
Zij:
- leest data uit bestaande systemen;
- combineert informatie uit meerdere bronnen;
- neemt beslissingen binnen vooraf gedefinieerde kaders;
- en voert acties uit in processen.
Dat betekent dat een agent niet naast je systemen bestaat, maar ertussen en eroverheen opereert. Een verbindende laag.
Wat bedoelen we met “een laag over je systemen”
In de praktijk bestaat een organisatie al uit meerdere systemen:
- ERP voor financiële processen;
- CRM voor klantdata;
- documenten, e‑mails en losse databronnen.
Deze systemen werken vaak naast elkaar en communiceren beperkt.
Een Ai‑agent vormt daar een laag overheen die:
- data uit meerdere systemen samenbrengt;
- context toevoegt;
- en acties terugstuurt naar die systemen.
Je vervangt systemen dus niet.
Je verbindt en versterkt ze.
De agent wordt daarmee een soort ‘coördinatielaag’: niet de bron van data, maar de plek waar data samenkomt en wordt gebruikt.
Wat er technisch gebeurt in die laag
Onder de motorkap bestaat die laag uit meerdere componenten die samenwerken.
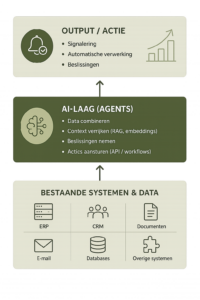
1. Data en context
De agent haalt data op uit bestaande systemen.
Die data wordt in moderne architecturen vaak:
- omgezet naar embeddings;
- opgeslagen in een vector database;
- gebruikt voor gerichte retrieval (RAG).
Hierdoor kan de agent relevante informatie ophalen zonder alles opnieuw te analyseren.
Belangrijk hierbij is dat je bepaalt welke data wordt meegenomen en welke data buiten scope blijft.
Die afbakening is essentieel voor controle.
2. Interpretatie en modelgebruik
Vervolgens wordt die data gecombineerd met:
- prompts of instructies;
- context uit eerdere stappen;
- modelinferentie.
Hier ontstaan beslissingen.
Niet door het model alleen, maar door de combinatie van:
- input;
- context;
- en configuratie.
Kleine wijzigingen in deze laag kunnen direct effect hebben op de uitkomst.
Daarom is inzicht bij deze stap cruciaal.
3. Orchestratie en uitvoering
De laatste laag is waar de agent handelt.
Hier gebeurt:
- API‑orchestratie;
- aansturing van workflows;
- uitvoering van acties in systemen.
Bijvoorbeeld een agent voor factuurcontrole:
- leest boekingen uit het ERP;
- haalt context op via een vector database;
- vergelijkt gegevens met regels en historie;
- markeert afwijkingen of verwerkt correcties;
- schrijft resultaten terug in het systeem.
Deze actie vindt plaats binnen de bestaande systemen, maar wordt aangestuurd vanuit de Ai‑laag.
Waarom de omgeving bepaalt of dit werkt
Wanneer deze laag buiten je eigen omgeving draait, ontstaat er een scheiding tussen waar beslissingen worden genomen en waar ze worden uitgevoerd.
Daarmee verlies je controle over:
- datastromen;
- modelgedrag;
- en besluitvorming.
In dat geval wordt de laag een black box tussen je systemen.
Wanneer deze laag binnen je eigen omgeving draait, verandert dat.
Dan is het:
- duidelijk welke data wordt gebruikt;
- inzichtelijk hoe beslissingen tot stand komen;
- en controleerbaar welke acties worden uitgevoerd.
De laag is dan geen onbekende factor, maar een expliciet onderdeel van je architectuur.
Impact op compliance en risico
Voor organisaties die werken met gevoelige, gereguleerde of bedrijfskritische data is dit direct relevant.
Wetgeving zoals GDPR en de Ai Act vraagt om:
- inzicht in datagebruik;
- controle over datastromen;
- uitlegbaarheid van beslissingen.
Als de Ai‑laag buiten je eigen omgeving draait, wordt dat lastig.
Niet omdat de technologie het niet kan, maar omdat de inrichting het niet ondersteunt.
Wanneer de laag binnen een private cloud-omgeving draait, wordt dat beheersbaar.
Je kunt:
- datatoegang afbakenen (bijv. via role‑based access);
- data scopen per use case;
- logging en beslissingen vastleggen.
Daarmee wordt Ai niet alleen krachtig, maar ook controleerbaar.
Waarom dit vaak wordt onderschat
De focus ligt vaak op wat Ai kan.
Automatiseren, versnellen, analyses maken.
Maar niet op waar het draait en hoe het is ingebed.
Daardoor ontstaat een patroon:
- snelle start;
- snelle eerste resultaten;
- daarna groeiende complexiteit.
Niet omdat de agent verkeerd werkt, maar omdat veiligheid en architectuur pas later worden meegenomen.
Wat dit vraagt van organisaties
Ai‑agents effectief inzetten vraagt om keuzes vooraf.
Niet alleen over use cases, maar over structuur:
- welke rol krijgt de Ai‑laag in je architectuur;
- hoe wordt data ontsloten en begrensd;
- hoe worden beslissingen opgebouwd;
- en waar vindt de uitvoering plaats.
Voor organisaties die Ai op eigen data willen inzetten, is dit bepalend.
Zonder deze keuzes blijft Ai een los experiment.
Met deze keuzes wordt het onderdeel van de operatie.
Conclusie
Ai‑agents zijn geen losse toevoeging aan je systemen.
Ze vormen een laag over je bestaande landschap waarin data wordt gecombineerd, geïnterpreteerd en gebruikt.
Juist die positie maakt ze krachtig.
Maar ook bepalend voor controle en risico.
De vraag is daarom niet alleen wat Ai doet,
maar waar die laag draait en hoe die is ingericht.
En precies daar wordt het verschil gemaakt tussen versnelling en complexiteit.




